Everybody Losing Sleep Over DeepSeek: Industry Implications to LLMs and AI Infrastructure
What a week: Open-source wins, AI Capex drops, False Trade-offs, BigTech freak out

I woke up to three newsletters on DeepSeek in my inbox today, and the day before, I think I received four. There has been A LOT of coverage of DeepSeek’s R1 and its implications, and you’ve probably even hit DeepSeek fatigue.
Nonetheless, given that the newsletter is called AI Proem, I feel I need to provide some analysis of what this breakthrough means for the LLM business model.
Don’t forget to like, share, and follow if you enjoy this piece. Thank you.
For the founder Liang Wenhao’s background and its V3 innovation, see here.
[For context and other perspectives, go to the very bottom. I’ve listed out the various opinions on DeepSeek the interweb has to offer]
DeepSeek's AI Breakthrough Sends Shockwaves Through Tech Markets
Headlines have mostly zoomed in on the fact that it only cost DeepSeek $6 million to train its latest R1 model, but it’s a little bit deceptive (which I’ll explain further below). What is undeniable is the shockwave R1 has sent through Big Tech. If better models can be built smarter and cheaper, what happens to the trillion-dollar AI infrastructure we just wrote about, the GPU arms race, and Silicon Valley’s “bigger is better” dogma?
Chamath Palihapitiya is one of the first to call it out as it is, “ AI model building is a money trap.”
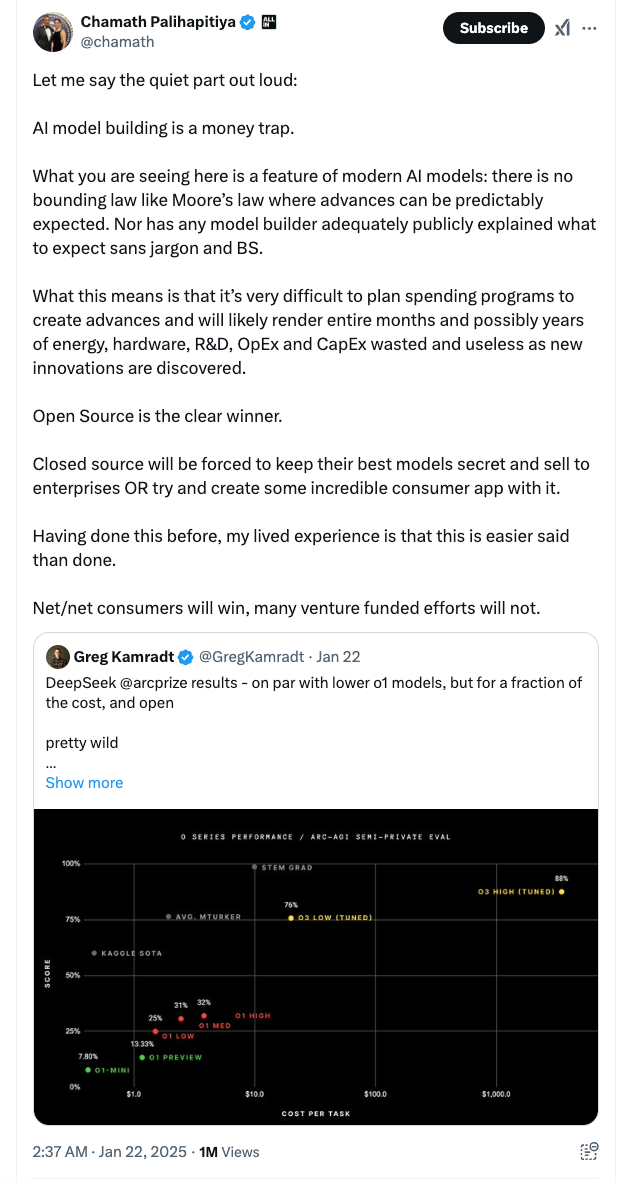
In a seismic shift that's rattled Silicon Valley, DeepSeek's cost-efficient AI breakthrough has triggered a massive tech sector selloff. Nvidia alone shed a staggering $600 billion in market value on Monday alone.
The Chinese startup that put Chinese AI on the global map with its V3 model, released in December 2024, has done it again. This time, it has released an R1 model that can achieve state-of-the-art AI performance at just 1/20th to 1/40th the cost of U.S. models. This has made global investors question the narrative that Big Tech has been telling: more money = better infra = better training = better AI.
Microsoft CEO Satya Nadella acknowledged DeepSeek's "super impressive" efficiency gains and urged the industry to take Chinese developments "very, very seriously." This revelation is forcing cloud giants like AWS and Microsoft Azure to reconsider their data center expansion plans, potentially spelling trouble for high-end GPU makers.
Many say DeepSeek's success using restricted H800 chips (rather than top-tier H100s) suggests a future where premium GPU demand might soften considerably (uh-oh, Jensen). While this spells uncertainty for traditional semiconductor leaders, it's creating opportunities in adjacent sectors like edge AI and automotive chips. For the AI industry, the message is clear: the AI gold rush is entering a new phase where efficiency, not just raw computing power, will determine market winners.
As one Wall Street analyst put it: "DeepSeek didn't just build a better AI model - they've forced everyone to rewrite their playbook for the next decade of tech investment."
Evolution of My Thinking & Context
About five months ago, we started with the thesis that the more AI we need, the more GPUs we will purchase, and the more power the hyperscalers will consume. The other half of the arms race was the ability to ramp up AI infrastructure quickly. Then, we re-assessed the AI Capex when o3 came out with its inference-time compute workings, especially when DeepSeek released its V3.
What R1 is doing now is that it’s “undo(ing) the o1 mythology,” wrote Stratechery. The tech analyst puts it eloquently: now, with the open weights, it means that instead of paying OpenAI (hundreds of dollars) to get the reasoning, you can run R1 on the server of your choice or even locally for free.
Various industry leaders have acknowledged the technological breakthrough that has led to a systematic paradigm shift in the AI value chain.
NVIDIA's statement after DeepSeek’s Monday drop: "DeepSeek is an excellent AI advancement and a perfect example of Test Time Scaling. DeepSeek’s work illustrates how new models can be created using that technique, leveraging widely-available models and compute that is fully export control compliant. Inference requires significant numbers of NVIDIA GPUs and high-performance networking. We now have three scaling laws: pre-training and post-training, which continue, and new test-time scaling."
What were the Breakthroughs?
In particular, the R1 had three major innovation breakthroughs:
Mixture of Experts (MoE) architecture: The breakthrough that was introduced in V2 allows the model to activate the “experts” that are necessary, but this implication wasn’t apparent until V3 (released during Christmas break). You can understand this as DeepSeek optimizing their model structure and infrastructure since they’re limited to using H800s and not H100s.
Think of MoE as a Michelin-starred kitchen where each chef specializes in one dish. When you order pasta, only the pasta chef works; the sushi and dessert experts stay idle. Similarly, R1’s AI activates only the “expert” neurons needed for a specific task, slashing compute costs by 70% or more.
Why it matters: Traditional AI models are like gas-guzzling SUVs. MoE turns them into electric scooters—nimble, efficient, and perfect for narrow tasks.
AI that teaches itself: Training most AI models requires armies of human annotators to label data. DeepSeek let “AI figure it out.” They used pure reinforcement learning, which lets the model learn through trial and error, like toddlers learning how to build Lego or stack blocks. The machine generates answers, gets feedback (e.g., “This math solution is wrong”), and iterates until it nails the problem.
Why it matters: This cuts costs and avoids biases often shown by humans. The caveat is that it can be riskier and more prone to the domino effect of mistakes. Letting AI self-teach could lead to really whacky “answers.” But DeepSeek seems to have worked on this front and tamed the chaotic hallucination results.
Model distillation: DeepSeek trained a massive “teacher” model, borrowing tricks from OpenAI’s models, and then distilled its knowledge into smaller, cheaper “apprentice” models (R1). Imagine breaking down a 1000-page textbook into 10-page cheat sheets by keeping only the core key formulas and concepts and removing the anecdotes and nice-to-haves.
Why it matters: R1 delivers ~ 90% of the performance of models 10 times its size at a fraction of their costs. The reduced model size allows you to run the DeepSeek model locally already. In a few years, it is very likely that models can be run on consumer devices like our laptops or smartphones.
What is This $6 Million Myth?
I think it was a very smart PR move. Some people are saying it was a big F-U to Stargate’s announcement, but honestly, the founder doesn’t seem to be dabbling in geopolitical play. Liang is just a nerd with grit. He probably just released the coolest new model whenever it was ready. In fact, the model was released one day before the Stargate announcement; it just wasn’t picked up by Western media until later.
The technical paper published by DeepSeek says that the $6 million does not include “costs associated with prior research and ablation experiments on architectures, algorithms, and data.” The $6 million covers ONLY the final training run on Nvidia’s H800 chips. At the same time, total cost, including prior research, has been estimated to come to “hundreds of millions” based on GPU infrastructure cost.
Why it matters: Let’s say the total cost is ~$500 million. Even at that, DeepSeek’s spending is still a fraction of what OpenAI has spent. OpenAI has raised a total of $16.6 billion in funding to date and has burned through most of that on the training and inference of all its models.
What’s mind-blowing is that despite not having access to the most advanced chips due to the U.S. chip ban, DeepSeek was able to innovate and reach the frontier model performance with H800s. Perplexity CEO Aravind Srinivas, on CNBC, said, "Necessity is the mother of invention. Because they had to figure out workarounds, they actually ended up building something a lot more efficient."
What Gavin Baker, CIO of Atreides Management, LP, pointed out also made sense to me: "What’s the point of restricting access to cutting-edge GPUs but not doing anything about China’s ability to distill cutting-edge American models? Why buy the cow when you can get the milk for free?”
So, I don't know. Maybe it’s better to work together or at least start competing on innovation.
All we can know for definite is that the previous AI industry playbook—” spend hundreds of billions to stay ahead”—is crumbling.
Industry Implications: Jevons Paradox?
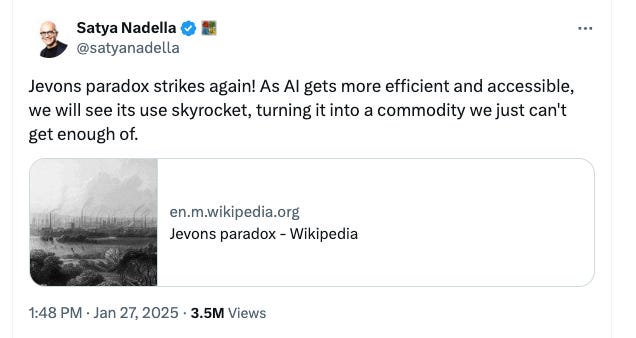
What is Jevon’s Paradox? The Jevons paradox occurs when the effect of increased demand predominates, and the improved efficiency results in a faster rate of resource utilization. (Wikipedia)
In layman’s terms, when technology becomes cheaper, usage explodes—even if it feels just "good enough." For example, in the 1800s, burning coal became more efficient, but instead of reducing demand, factories used more coal to power new machines.
Similarly, suppose AI becomes more affordable (DeepSeek R1 is currently much cheaper than other frontier models). In that case, we can probably expect startups, governments, consultants, and even schools to all use way more AI than they are using today.
But for Jevon’s Paradox to kick in, we need real AI applications, killer apps that will reshape the way we live and work. Just like in the Internet era, we had Google, Facebook, Amazon, etc. Today, we are still waiting for AI’s Google moment (Microsoft’s Co-pilot clearly didn’t cut it…). In terms of applications, I think Chinese tech companies may actually have an edge in consumer-facing application innovation — see why here. Also, check out Bytedance’s Doubao (China’s ChatGPT)’s exploding usage already.
Model Commoditization and Cheaper Inference: Big Tech and AI Infrastructure
I’ve previously written about hyperscalers feeling FOMO and just chucking money at AI, thinking it’ll help increase their competitive advantage. But the AI spending spree might have just hit a wall. While it might not be bad news for big tech in the long run, they definitely need to reconsider their approach to AI investment in the near term.
In the near term, DeepSeek’s R1 has triggered an existential crisis for frontier AI companies (OpenAI, Anthropics) and hyperscalers (Microsoft, Google, Meta, Amazon). These firms may all need to rethink their spending on AI and may be receiving questions on whether they have wasted hundreds of billions of dollars.
DeepSeek rewrote the scaling law, which was simply more money => more compute => bigger model => better model. Suddenly, the game isn’t about who has the deepest pockets but who has the cleverest or savviest innovations. The new scaling law now includes an added element of human innovation and ingenuity.
For chipmakers and energy companies — the assumption has been that better models require more chips and thus require more energy, so chips and energy demand would just keep increasing as models become bigger and bigger. However, as the industry rethinks near-term training capex, hyperscalers may delay or shrink data center projects, hitting chipmakers like Nvidia and power providers like Vistra.
In the long run, model commoditization and cheaper inference could be good news for Big Tech and start-ups. This will significantly decrease the spending required by hyperscalers on data centers, energy, GPUs, and all the AI infrastructure surrounding them. So although on the surface, Meta (Llama), Microsoft, Amazon, and Google are getting whipped in the public sphere on why they were not able to produce something as advanced as DeepSeek’s model with a much bigger budget, in the long-term, the big boys might not be big losers after all. Lowering the cost of training and inference will increase the ROI on AI.
On the old scaling law, one interesting question is, was this all a big capitalist scam? Was the trade-off of energy/resources/water/environment for better AI always just a way to hoard more capital? See veteran AI journalist Karen Hao’s X thread, which is very insightful.
Ultimately, DeepSeek’s R1 is now competitive with OpenAI’s o1, and we see Sam taking to X and going into full combat mode.
Additional Thoughts
Another reason this DeepSeek release has received so much media frenzy and international attention is because of the bigger shocker that legitimate innovation is coming out of China when the headline or stereotypes have always been “China is good at copying.” This is a wake-up call for the U.S. AI industry, that a real competitor is quickly catching up.
Next is the big debate that this is a win not for China but rather should be seen as a win for open-sourced vs. closed. The open-source nature of DeepSeek, which the founder has said was a decision based on his personal philosophy but also for collaborations and talent attraction. Whatever his reasoning is, DeepSeek benefits small and medium-sized businesses and consumers the most – any software, internet company, or business globally that wants to integrate AI into its workflow. Basically, people who previously wouldn’t or couldn’t pay to try out the latest frontier model can now have a crack at it.
I’ve quickly listed out the various angles/ opinions on DeepSeek’s R1 release below. The most common fearmongering theme by mainstream media and some China hawks has been, “OMG. This is when China’s AI takes over the US, and the CPC will take all our data.” Sure, there are geopolitical implications, as we have also covered, but this really goes beyond that. I guess it’s fine to call it the “Sputnik moment.”
Yann Lecan led the more nuanced comparison, saying that this “win” reflects open-source's victory over closed-source. (echoed by Chamath, see X)
Veteran AI journalist Karen Hao’s take is that this shows the billions and billions “needed” by LLM companies were, in a way, a capitalist scam, maybe not a scam, but for personal gain reasons. The tradeoffs of energy consumption/ climate damage/ resource waste for better AGI were a narrative, not the truth. (which I touched on as well here)
See
’s piece that answers some of the FAQs on this DeepSeek R1 release.And to learn more about DeepSeek R1’s specific specs, check out Geopolitics’ post.
I wrote about the founding background here previously.
There have been talks about this reflecting China’s innovation prowess, but
writes an interesting angle here. DeepSeek is the anomaly, unlike other Chinese market leaders, such as EVs or renewable energy, which were driven by top-down policy and capital and talent encouragement.This interview with Lennart Heim and Sihao Huang is also very good as it provides context on the issues that the headlines have missed, such as: a) DeepSeek trained on H800, which were designed to circumvent the October 2022 controls but are still very high performing chips. b) The real export restrictions on advanced chips started in October 2023. c) Overall, machine learning algorithms have become cheaper over time. d) Check them out. I cannot judge the technicalities well, but I thought it provided some extra color.
Perplexity’s co-founder, Aravind Srinivas, went on CNBC to talk about the meaning of DeepSeek’s innovation. Various other industry leaders expressed that the U.S. chip ban seems to have forced Chinese scientists to be more creative and build something more efficient. This milestone success has allowed Deepseek to be embedded into the global AI infrastructure.
There has also been some interest in the talented engineer Zizheng, who interned at NVIDIA in the summer of 2023 and decided to join DeepSeek.
Last but not least, for Funsies
We also played around with DeepSeek last night. See the thread and how its brain works behind the scenes.