


Release of OpenAI's o3 has completely changed the debate on whether AI scaling law has hit a wall
AI scaling law, OpenAI o3, inference-time compute breakthroughs, synthetic data

Hello, happy 2025! Welcome back from the holidays. Hope you had a restful time with loved ones.
I’ve been mulling over how AI may evolve in 2025, and the AI world seems to be busy despite the holidays. I guess they’re practically running like robots now.
Over the last two weeks, there have been quite a few big releases, including OpenAI’s o3 release and Deepseek’s V3 release. These announcements made me ponder all the things I’ve been rambling about and want to learn more about the technicalities of AI training.
So, I spoke to some friends who are much, much, much smarter than me (Math majors from Princeton, CS PhDs at MIT, and investors in energy and real estate) to pick their brains and get them to explain the technicalities to me.
Below are some of my thoughts and notes from recent discussions on pre-training scaling laws and recent breakthroughs in inference-time computing.

Healthy Skepticism?
Before the o3 model release, I read a few of Gary Marcus’ long blogs, not because I’m no longer bullish on AI but because he’s so outwardly bearish. When the world is hyped with headlines like AI will take over your jobs and whatnot, this guy seems to be confidently contrarian and making some fair arguments against technological development. So, in my quest to understand the “scaling laws” and their implications for our real world, I was intrigued by this skeptic’s views.
In his 2022 viral article “Deep Learning is Hitting a Wall,” he wrote, “Few fields have been more filled with hype and bravado than artificial intelligence. It has flitted from fad to fad decade by decade, always promising the moon and only occasionally delivery.” — Gary Marcus.
Marcus pointed out, “Scaling laws aren’t universal laws like gravity, but rather more observations that might not hold forever, much like Moore’s Law,” which was held as the golden rule for computer chip production until about a decade ago.
This was echoed by the Princeton computer scientists and authors of the book and Substack, both titled -
, Arvind Narayanan, and Sayash Kapoor. In June, the pair pointed out that the “popular view” of the more (data), the better (models) “rests on a series of myths and misconceptions,” highlighting that LLM developers are at the limit of high-quality training data. Adding that “every traditional machine learning model eventually plateaus; maybe LLMs are no different.”When I covered the US hyperscalers earnings from last quarter, the executives focused on echoing each other: bigger models equal better models, and the risk of underinvesting in AI is higher than the risk of overspending. Their message was pretty much - if you don't do it, you’ll be left behind, the ultimate FOMO.
But that narrative shifted slightly over the last few months…
Major news headlines seemed to have shifted the focus from the models' size to AI companies’ “strategy shifts” due to scaling law potentially hitting a wall. AI skeptic Marcus suddenly wasn’t alone in his skepticism.
Marc Andreeson at Andreeson Horowitz said on a podcast just a month ago that “we're increasing [GPUs] at the same rate. We're not getting the intelligent improvements at all out of it.”
Even he was essentially saying, “Yup, scaling laws are no longer working.”
What was the Conundrum?
There are four areas of constraint in the scaling law:
Data Scarcity: The argument here is that we have already used all the available human-generated text data on the internet, and now we can only use synthetic data (data generated by AI) to train. However, many argue that synthetic data is not reliable.
Power Shortage in the U.S., which I’ve written about extensively here.
GPU Production: Can we produce enough GPUs/ use any alternatives as compute demand continues to increase?
Moore’s Law predicts that the number of transistors on a microchip doubles roughly every two years, driving technological advancements. However, this trend faces significant limitations. One key constraint is the size of atoms; as transistors shrink to the atomic scale, they cannot be made smaller than an atom, creating a hard limit on chip size. The most cutting-edge chips are already manufactured at a scale of 2 nanometers.
The challenege here, some people argue, is that if you just increase the number of GPUs while you still have the same amount of training data, then the model training outcome will hit diminishing returns on the additional GPUs added. Any of these constraints above could be the limiting factor for further AI scaling.
Then, some might argue that look at how much money the big tech firms have spent and are still spending on AI training. They must know what they’re doing and believe that the scaling law still holds despite the challenges?
Well, some corporations, academics and investors want the Scaling Law to be true because:
When the law basically meant more money = more results, then it offered predictability and reliability, which for corporates who have invested upwards of over US$200 billion (some estimate are closer to US$300 billion), they want to know that their investment will be generating returns
Scaling reliability also worked in academics' favor. This means that new model performances could follow existing benchmarks and would be easier to track and compare for research purposes.
We cannot deny that Wall Street liked the narrative, too. It was straightforward when “bigger = better,” so the investment thesis was also simplified for them.
New Perspective: OpenAI o3 Breakthrough
If you drop off from reading the article here, you would have probably thought I think the scaling law no longer holds. Then, as I mentioned, I was enjoying the wine and snow in Hokkaido, Japan, and OpenAI’s latest model, o3, dropped and surprised everyone.
Before OpenAI’s o3 release, the argument about whether the scaling law still works was starting to skew toward the idea that it may not. However, o3's achievement represents a turning point in this debate. Even Francois Chollet, a vocal critic of the ability of large language models (LLMs) to achieve general intelligence, seemed to have softened his skepticism.
Paraphrasing boutique TMT-focused New Street Research’s analysis, o3 leaves previous-generation models in the dust.
In a test consisting of real-world complex software engineering tasks, o3 achieved 71.7% accuracy, a >20pt improvement over o1’s 48.9%. For context, a proficient software engineer would score ~75% on this test, showing that o3 performs on par with a high-caliber human.
In a test for measuring competitive coding capabilities (genius coders compete in coding contests), o3 scored 2,727 Elo vs. o1’s 1,891. For comparison, OpenAI’s head of research, Mark Chen, is a competitive coder with around 2,500 Elo. o3 ‘s abilities is on par with some of the best human coders.
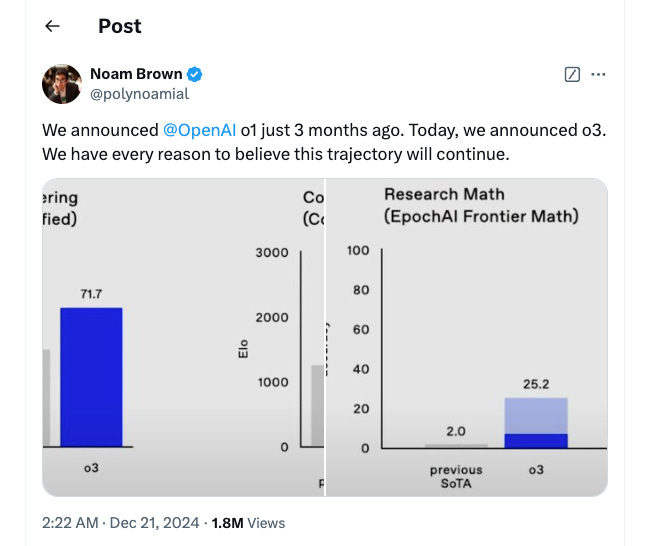
Link to X post from Dec.21, 2024
How did o3 do it?
It all started with the paradigm shift we saw when OpenAI released its “Strawberry” o1 model in September with “reasoning abilities,” which were significantly enhanced in its subsequent o3 model.
The new concept is called “inference-time-compute,” which New Street Research wrote in a report saying that o3 likely combines deep learning (a multimodal LLM) with program synthesis, or in other words, “the ability to create a new program when facing an unknown task.”
“In simple terms, the model likely develops a very large number of possible chains of thoughts to execute a task, organized as a tree of chain steps, and evaluates which trajectory is best, evaluating with a gain function the quality of the chain of thought and/or the intermediary output.” — New Street Research
In layman's terms, the previous generation of models, such as GPT4, gives output straightaway. The new generation of models with inference time computing can repeat, reiterate, and recalibrate their thought processes before giving their final output. This looks more and more like human thinking. [Wharton Professor
has a write-up here that was helpful.]
What is inference?
When you ask ChatGPT a question, the model reacts and gives you an answer, which is called “inference.”
In more technical terms, after a model has been trained on a dataset and learned the underlying patterns, “inference” means generating predictions about new inputs or unseen data.
"Training is like going to school. You learn a lot. Inference is like what you do after you graduate. You go out and do useful things." — Jensen Huang on BG2 podcast (Episode 17 titled "Welcome Jensen Huang)
What is Chain of Thoughts?
Inference computing helps the models improve as we give them more time to repeatedly ask themselves if the answer they provide to a certain prompt is reasonable. This is similar to how humans think through more complex issues. The process of continued prompting, with the aim of incorporating logical steps and reasonable thinking, is referred to as a “chain of thoughts.”
Game Changer: Synthetic Data
Wait. I understand that reasoning-time computation is impressive, but what about training data? Previously, a key bear argument has been that we will run out of high-quality training data very soon. Yes, the new models can think for longer, but does more thinking matter without data?
Some say the answer lies in synthetic data, which is data generated by AI models that are used to train more AI models.
The Information reported in November that “Many labs have turned to synthetic data, or data generated by AI, to train their models.” There just isn't enough so-called “fresh” data to train on further.
Some argue that synthetic data can only really be used to fix specific gaps or issues arising from real-data training. AI Snakeoil points out that synthetic data aren’t really used to “increase the volume of training data,” and replacing current sources of pre-training data will likely not be viable.
On the flip side of the argument is Dylan Patel from
, who said on B2G podcast recently that the key to using synthetic data is making sure you can do “functional verification.”Here is an example of how it works: say you want to generate more training data on programming because you ran out of human-written programs to train models. You ask the model to generate a TON of synthetic codes, filter through them, and only keep the correct ones for training new models. With this new axis of synthetic data, we can just “compute more”, “throw-away” the bad data, and keep the good data to train and improve the models. This may lead to faster progress and improvement than what we’ve ever seen.
You might raise a question then: How do we know which synthetic data to keep and which to discard?
Initially, human graders graded the training data (a lot of which is happening in India and is going unnoticed). However, as the training data size quickly grew, human grading was no longer scalable. This brings us back to the functional verification point, which means using AI to grade themselves.
Fields like competitive coding and math lend themselves well to verification as “true” or “false”, making them prime candidates for benefiting from this type of synthetic data in AI training. In these fields, as shown above, the o3 model already scores better than most humans.
However, some argue that this approach could also be extended to other fields like social sciences or creative work, although it may require more effort in the verification step. What we know is that it currently does well in certain domains but not others, and we cannot teach models subjective preferences, such as verifying the quality of the art. I believe there are still limitations to consider when applying synthetic data to those areas.
The final point about synthetic data is that we’re still in the very early days of exploring how to better utilize it. According to Patel, the industry has invested hundreds of billions in model training while having only invested tens of millions in synthetic data so far. One may argue that with more focus, capital, and time, the industry will improve the quality of synthetic data and/or find more creative ways to treat the data, so that finding quality data itself would no longer be a hurdle to scaling.
Stay Tuned
Thank you for following my chain of thoughts as I tried to understand the scaling law argument. From where I am sitting now, the scaling law seems to still hold, and models will continue to improve.
However, that is a trillion-dollar question that no one knows for sure. That’s for another piece, which I believe is important to apply a probabilistic approach and analyze different scenarios.
Stay tuned for a scenario analysis of whether or not the scaling law holds, and what that means for different businesses…
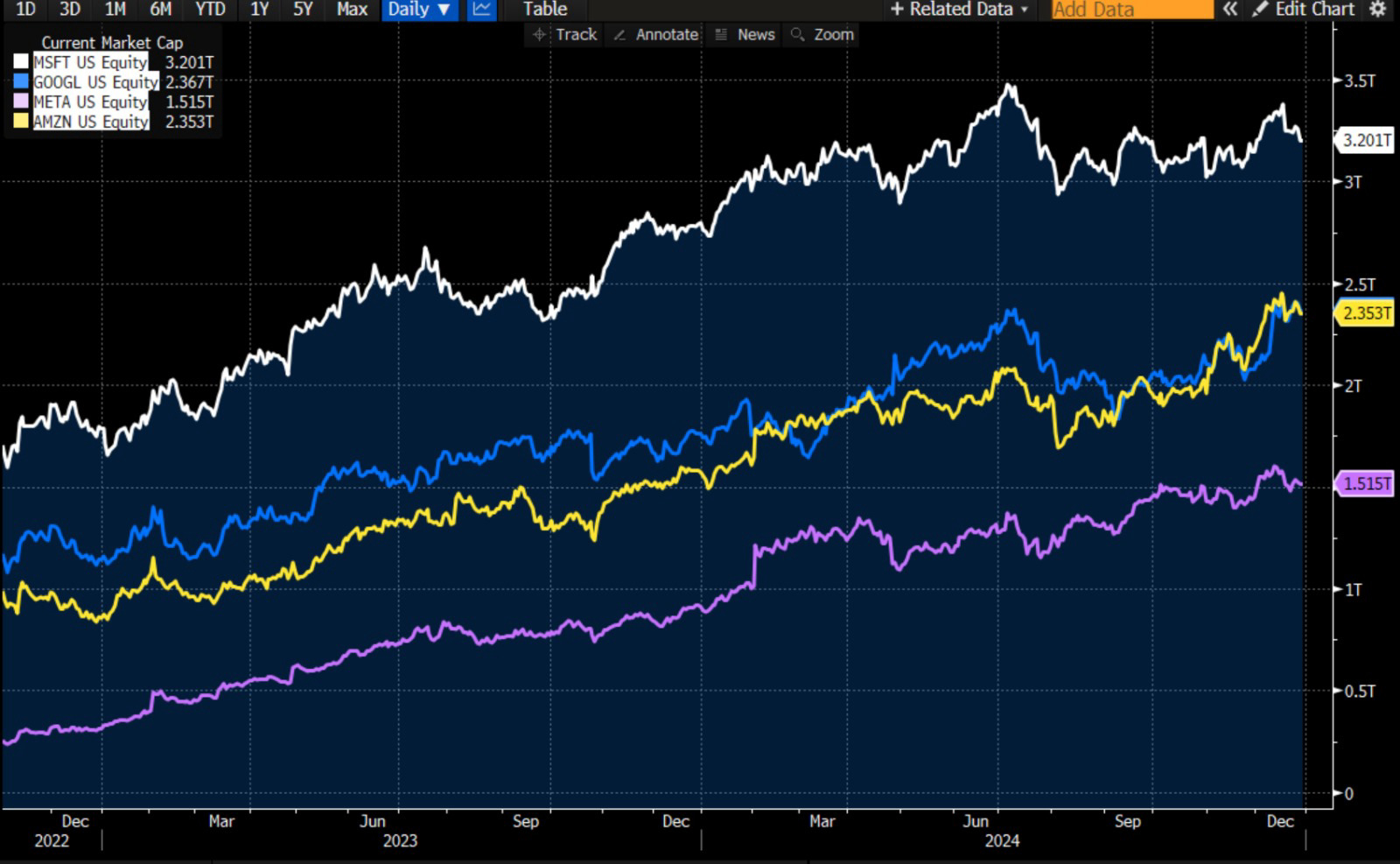
Since the release of ChatGPT (Nov 30, 2022) and the thrust of AI on the general public, the big four in the U.S. have added $4.1 trillion to their market cap…