
China’s ChatGPT Doubao shows that inference compute demand COULD actually go up by 1 billion times.
Quick hot take: ROI will be in inference, and hyperscalers move away from pre-training compute

Hi all, the talk of the town is Deepseek, and I acknowledge that I haven't written a follow-up to the DeepSeek V3 Puts China AI on the Global Map: Consumer Use and Capital Expenditure Implications piece yet. The thing is, whenever there is SO much buzz and opinions around a topic, I want to observe first.
I will work on a piece on what I think the potential business and market implications are. But first, a quick TL;DR: 1) Will AI capex go down? Siemens Energy (which sells gas turbines for power generation) sank as much as 20% today. 2) ASML’s stock prices crashed as much as 10%. 3) The Nasdaq 100 futures dropped, and Nvidia dropped close to 10% pre-market. This is probably only the beginning of a correction to the hype.
In addition, the DeepSeek R1 release has made people question whether it is necessary to have advanced chips for better models and the effectiveness of the U.S. chip export bans on China—which the founder of DeepSeek has explicitly said before. They would prefer they had more advanced chips; it’s just that they were forced to figure out a more cost-effective and technically efficient way using less advanced chips. Anyway, I will look into this more and share a few thoughts. (although there really are enough thoughts floating around the internet already)
Again, please hit like, share, or subscribe if you enjoyed reading this/ found it amusing/valuable. Or DM me and tell me it’s absolutely crap and how I can make it better. Honesty is always appreciated.
There has been a heated debate about whether investors and hyperscalers should continue to chuck billions at further training computing or focus more on inference computing. While OpenAI does not disclose its inference demand directly (it does disclose that inference compute is roughly ⅓ of its total compute cost; OpenAI’s inference demand includes APIs, which means, if, say, Deepseek is using OpenAI inference to train its own model, that counts as inference for OpenAI; hence, real inference demand of OpenAI is not disclosed).,
China’s ChatGPT, Doubao, developed by Bytedance, just disclosed its inference demand trendline last week. And look at that wild growth trend below.
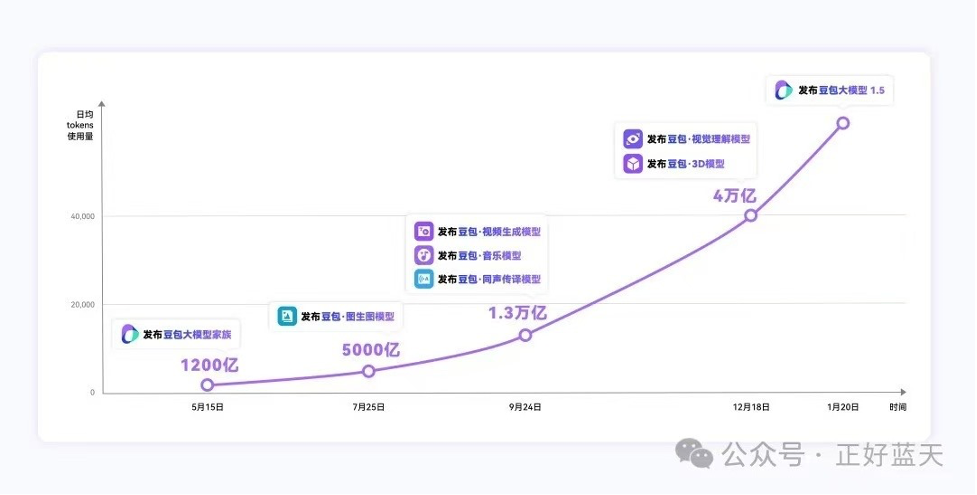
Translation: the purple curve tracks Doubao’s increasing inference token consumption from May 2024 to January 2025:
Beginning at 120 billion inference tokens per day (May 15, 2024) with the launch of their foundation large language model
Expanding to 500 billion inference tokens per day (July 25, 2024) as they deployed their model with photo-generating capability
Growing to 1.3 trillion inference tokens per day (September 24, 2024) with the introduction of specialized models for video content, music generation, and voice synthesis
Reaching 4 trillion inference tokens per day (December 18, 2024) as they rolled out more advanced capabilities, including visual understanding, 3D modeling, and their large model version 1.5
The chart here demonstrates ByteDance Doubaos’ exponential growth in AI inference computational scale, measured by the number of tokens processed for actual model usage rather than training. The progression shows wider adoption and practical implementation of their AI products, as each new model release contributes to higher inference demands from actual usage.
So, who’s to say OpenAI’s inference chart does not look like Doubao’s? Who’s to say that inference demand won't increase by 1 billion times in the long run, as Jensen Huang had predicted? The thing is, OpenAI has been so secretive about its pre-training and inference compute figures that we can only reference this as it is one of the first somewhat comparable LLM firms openly disclosing its token usage.
So it brings us back to what we’ve tried to understand before: does the pre-training scaling law still hold, and how will it impact GPU demand? (check this piece out on scaling law; I actually think I did a good job here)
For Nvidia’s Jensen Huang, he’s been saying that the world will need his GPUs whether it’s pre-training or inference demand. However, inference “is about to go up by a billion times,” Huang said during an interview with venture capitalist Brad Gerstner on the B2G podcast. In October last year, around 40% of Nvidia’s business was for A.I. training, and another 40% was for A.I. inference. (The remaining 20% of revenue comes from its traditional video, gaming, and automobile products.)
He said we need to shift how we look at it. Training models is like “going to school,” but the ultimate goal is to train models to perform real-world tasks like “inference.” This is like us getting a ton of degrees, and they’re useless unless you can perform in a job (in most jobs). And delivering results on the job is probably the most important. Thus, he believes that inference demand will become the real demand as we move ahead in this AI journey.
Which takes me to the point I want to highlight: “That’s the part that most people haven’t completely internalized…This is the Industrial Revolution…It’s [inference demand] going to go up a billion times.” — Jensen Huang, Nvidia CEO
What is the training vs. inference demand argument (o1’s chain of thoughts & training’s scaling law)? See here.
What is the argument that lower investment into training can still = a good model, so investment into training will likely go down (DeepSeek primer)? See here.
What does 4 trillion inference tokens per day mean?
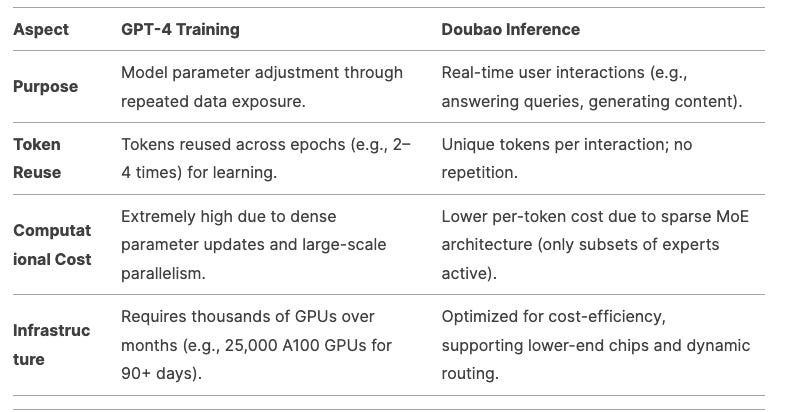
Looking at this top-down. First the rumors are, OpenAI used ~11-13 trillion tokens to train GPT4. We can see that Doubao’s current DAILY token use is already one-third of that, and it would only take ~3 days for Doubao’s inference demand to consume as many raw tokens as it would take to train a GPT4! Obviously, this comparison is not apples to apples.
Model training would require tokens to be reused multi-times vs. inference is just one time without repetition. Also, for the same amount of tokens, training will consume more compute due to high parameter count whereas inference for Doubao is handled by smaller models with lower parameter count. All this is to say that training is still far more compute intensive than inference (see chart below), even if headline token numbers look similar. But you finally get my point on how big this 4 trillion is and why it is relevant!
Now, let’s look at this bottom-up to conceptualize what 4 trillion tokens can do. Today, if you ask Perplexity a normal complex question, on average, it will consume ~500 input/output tokens (based on an assumption of 500 tokens = 375 words, just enough for planning a travel itnerary or 3-4 back-and-forths on a topic). Doubao has roughly 9 million DAUs as of Dec 2024 (daily active users). If we divide the 4 trillion daily token consumption by 9 million, that would mean each DAU is consuming 4.4 million tokens per day, which would mean each DAU is asking Doubao nearly 9,000 questions (4.4 million divided by 500) every day!
But of course, that’s not really logical, actually quite absurd of a number. No one is asking Doubao that many questions, at least not yet. So there are better explanations of why daily token consumption is so high.
First, inference time compute means sometimes Doubao will break down one question into multiple questions when answering, so the token consumed can go up one order of magnitude larger than just answering one question. With the hugely reduced cost of inference shown by the DeepSeek R1 model that has been widely talked about recently, we can be certain again that inference can be scalable at an affordable price (relatively).
Second, Doubao disclosed that it currently powers industry-specific applications in more than 30 industries. Hence, we can assume a large amount of daily consumption is used by enterprises inference demand, which makes more sense for the scale.
Third, token consumption can increase greatly when the model is multimodal. If you ask AI to generate one photo, on average, it will consume 500 tokens. This is similar to the token intensity of a text question and answer. However, if you ask AI to generate an one-minute video, depending on resolution, a one second video consists of 24-60 pictures, so you can do the math.
If we assume 24 pictures per second, then one minute of video is 60 x 24 = 1,440 pictures. Tokens consumed for generation one minute of video is 1,440 x 500 = 720,000 tokens.
Inference demand increases by three orders of magnitude when the user starts generating videos (720,000) vs. pictures/texts (500-1,000).
With video generation, 4.4 million tokens per day just means merely 6 minutes of video generated using AI.
btw if you think there is something severely off about my assumptions/ calculations, please do let me know, legit grateful.
And this is just video usage; now, imagine the token density when AI starts doing 3D. This aligns with Doubao’s disclosure—it launched a photo generator in July, video in September, and 3D in December. Token density is exploding as Doubao becomes multimodal.
Still, 4.4 million tokens per day per DAU is a lot of tokens, meaning Doubao users are using the platform extensively. More importantly, the fact that Doubao ‘s total daily token count grew so fast really shows the potential for explosive inference growth. Let’s do some quick math on theortically how much this can grow.
Inference token = number of DAU x token density
Douyin, the Chinese version of TikTok, has a DAU of 750 million. Thus, Doubao’s DAU could theoretically grow >50x (from currently ~9 million).
Today, token density is 4.4 million tokens per day per DAU (which we calculated above as just 6 minutes of video generated per day). Users can certainly generate far more AI content than just 6 minutes of video per day, and token density can also grow one order of magnitude.
This means Doubao’s total inference token can still grow multiple hundreds of times off the current level. So let’s wait and see what Doubao disclosed in January - their token consumption is growing at a 50% month-over-month rate to roughly 6 trillion tokens per day already.
Pivotal Moment for Microsoft & OpenAI’s Relationship - Stargate
OpenAI has partnered with Japanese investment firm SoftBank and an Emirati sovereign wealth fund to build $500 billion of artificial intelligence infrastructure in the United States.
Just last week, President Donald Trump announced the new company, The Stargate Project. He billed it as "the largest AI infrastructure project by far in history" and said it would help keep "the future of technology" in the U.S.
How does this inference ah-ha moment all link back to the most recent Stargate deal?
Gavin Baker, Managing Partner and Chief Investment Officer of Atreides Management, LP. Long-term tech and semi-investor took to X to share his hot take on the Stargate deal. See tweet [here].
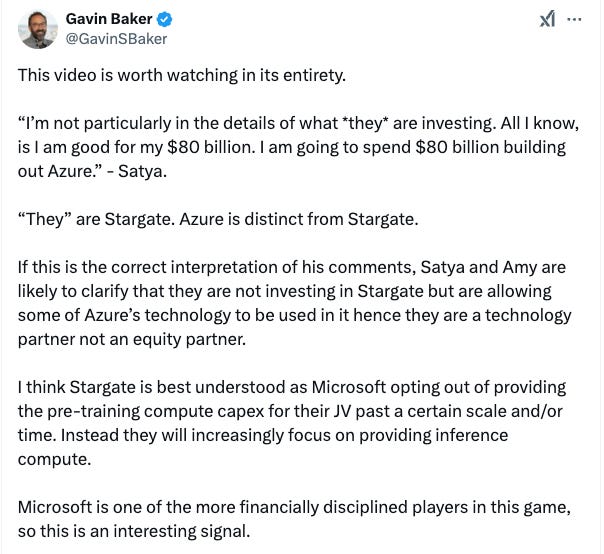
He thinks that Microsoft definitely had its first dibs on the Stargate deal but turned it down strategically.
Satya is essentially the only “adult” here and rationally thinking that there is no point in wasting $500 billion to train the model.s
Baker wrote that Microsoft is “opting out of providing the pre-training compute capex for their JV past a certain scale and/or time. Instead, they will increasingly focus on providing inference compute.”
Microsoft will keep its $80 billion investment but that will be for multiple usage (and not just for pre-training)
Quoting Microsoft Satya Nadella’s interview, “I’m not particularly in the details of what *they* are investing. All I know is that I am good for my $80 billion. I will spend $80 billion building out Azure.”
Baker writes, “If this is the correct interpretation of his comments, Satya and Amy are likely to clarify that they are not investing in Stargate but are allowing some of Azure’s technology to be used in it hence they are a technology partner not an equity partner.”
Baker added that because “Microsoft is one of the more financially disciplined players in this game, so this is an interesting signal.” highlighting that the ROI on AI has shifted to focus on inference.
And given the context that recent models such as o3 and R1 models (see DeepSeek primer here) have “showed that the biggest future improvements in model capabilities are likely to come from RL during post-training, synthetically generating reasoning traces and test-time compute. These are all essentially inference (ish in the case of RL).”
Hence, Microsoft's move clearly signals that the hyperscalers are shifting from pre-training compute to inference compute. And this might also be the start of the decoupling or at least distancing between Microsoft and OpenAI.
and I guess Elon Musk agrees, as he gave Gavin a bullseye 🎯 See tweet [here]. Again, proving INFERENCE IS THE FUTURE ROI.
And this is the perfect segway to DeepSeek's R1 and what it means for the LLM business model. People are so worried about compute-demand going down as DeepSeek is so much more efficient BUT what if total demand for inference sky rockets and goes up by 1 billion times? Stay tuned.