
DeepSeek’s Open Source Week: Sharing the Future of AI Efficiency
Why DeepSeek is embracing Open Source

Sorry for the later-than-usual post this week; I was a bit under the weather.

OK, SO…
Last week, DeepSeek held an “open source week” to disclose details about its low-cost, high-performing models. However, the event largely went unnoticed by the media—at least not discussed in terms of its implications. It did, however, make waves in the open-source community.
Over the course of six days, the company released tools that aim to redefine how artificial intelligence is developed and deployed. These tools promise to make AI faster, cheaper, and more accessible, not just for tech giants but also for smaller players.
Many people have asked me why DeepSeek is embracing Open Source or why Chinese tech seems to be more keen on the open-source model. I think there might be a few reasons.
For DeepSeek, it really is a personal philosophical choice for CEO Liang Wenfeng.
For China, in some ways, it could be a bit more personal - a chip on their shoulders. For decades, the world has pointed fingers at China for “copying” innovation, for better or worse, often offering cheaper and better-copied goods. However, for the generation of entrepreneurs born in the 80s and 90s, there has been a desire to really prove to the world that Chinese companies can, in fact, innovate. And we’ve seen that especially come through the internet era with TikTok, Shein, DeepSeek, Unitree, etc. And Kevin Xu coined it quite eloquently - the rise of the “开元情怀 open-source zeal” - where it is more exciting to be quoted/ used by developers and businesses outside of China than making money off of the project.
On top of that, the overly heated fear around China’s tech innovation is partially driven by real concerns of state security in the U.S., as obviously, whichever country can have a grasp on the most frontier technology will also mean having a global influence on economies, societal expectations, and military prowess. But that’s only half of the argument, I think. The other half that feeds into the fearmongering narrative is also partially fueled by the fear of competition and, again, that, in a way, drives firms to want to show off their capabilities, maybe. Nonetheless, these have been the dual drivers of fearmongering about Chinese tech in the U.S. around consumer apps like TikTok, Shein, and RedNote.
I think the open source model is widely accepted and preferred because of the ecosystem’s monetization strategy.
and I wrote about the divergent commercialization strategies the U.S. and China are adopting—specifically, why many in China expect free LLM and commercialization is at the application end.[added after initial publishing] Adding to the initial thoughts, I am including another hot take by Kevin Xu that I think is super interesting. He wrote, “open source is the equivalent of soft power in tech,” in a way, an ultimate flex.
Anyway, it’s interesting to see the Chinese tech and AI companies really getting a boost to the front row again after a dull few years for the Chinese internet sector.
What Is DeepSeek Open Infra Week?

Day 1: FlashMLA
What It Is: FlashMLA is like upgrading your car engine to go faster without burning extra fuel. It’s a tool that helps AI systems process information more efficiently on GPUs (the hardware behind most AI models).
What It Does: It optimizes how GPUs handle variable-length data (like sentences of different lengths), making them faster and more memory-efficient.
Why It Matters: This means companies can run AI models more quickly without needing expensive hardware upgrades. For users, this could translate into faster responses from AI systems like chatbots or recommendation engines.

Day 2: DeepEP
What It Is: DeepEP improves how computers “talk” to each other when training massive AI models. Think of it as upgrading from a bumpy dirt road to a smooth highway for data transfer.
What It Does: It speeds up communication between GPUs and uses a lightweight data format (FP8) to make everything run more smoothly.
Why It Matters: Training large AI models often takes weeks or months. By reducing delays, DeepEP makes this process faster and cheaper, helping smaller teams compete with industry giants.

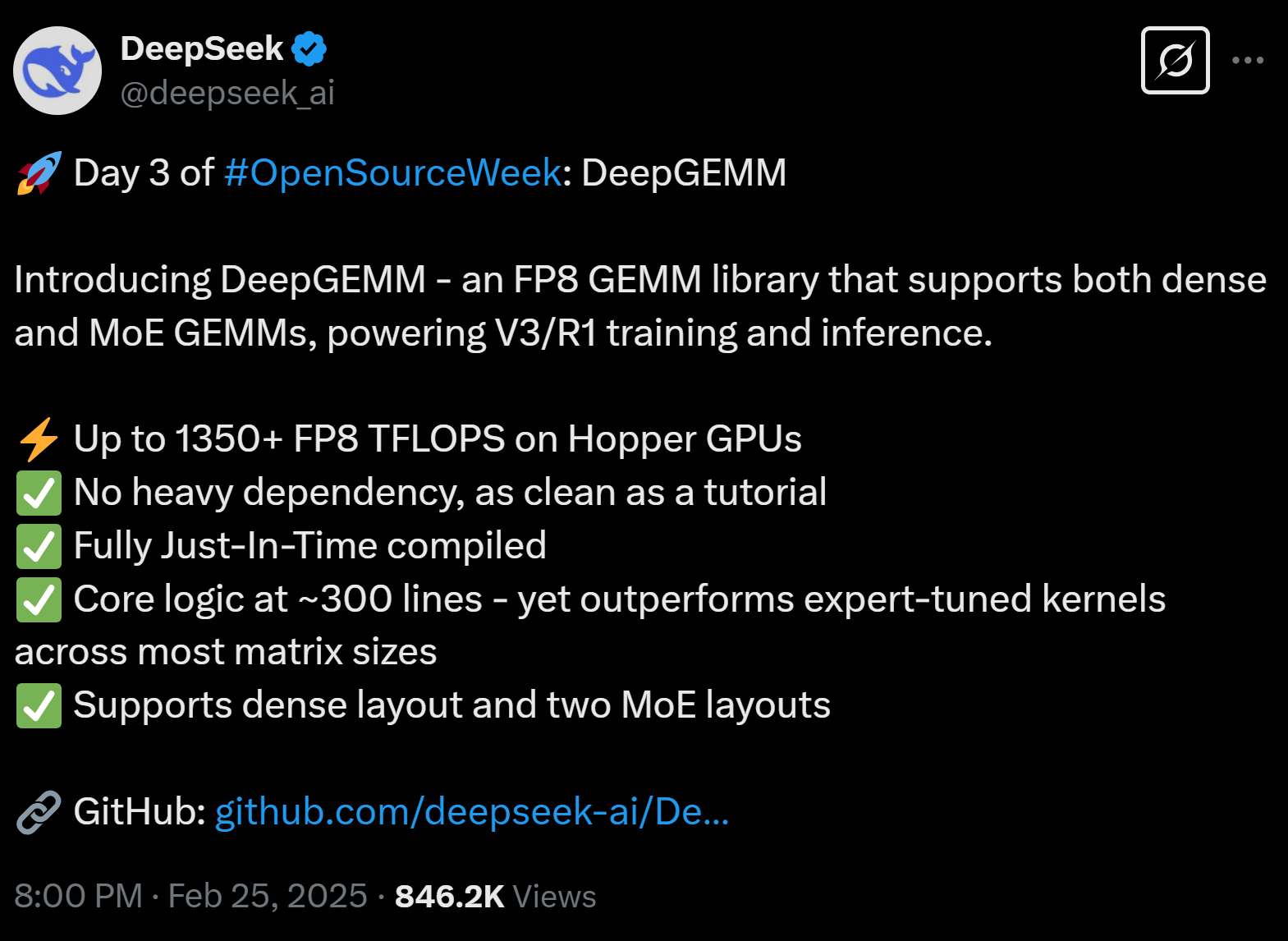
Day 3: DeepGEMM
What It Is: DeepGEMM is like installing a super calculator in your computer. It handles the heavy math that powers AI systems with record-breaking speed.
What It Does: It processes calculations 10 times faster than older tools while using less energy.
Why It Matters: Faster math means quicker training for AI models and real-time applications like voice assistants or translation tools that respond instantly.
Day 4: Optimized Parallelism Strategies
What They Are: Two new strategies—DualPipe and EPLB—designed to help GPUs work together more efficiently.
What They Do: DualPipe ensures GPUs don’t waste time waiting for instructions, much like an assembly line where each worker knows exactly what to do next. EPLB balances workloads so no GPU is overwhelmed or underused.
Why They Matter: These strategies allow companies to train massive AI models faster and at lower costs, opening the door for even more complex and capable systems.

Day 5: Fire-Flyer File System (3FS)
What It Is: 3FS is like upgrading your computer’s storage system to handle huge files at lightning speed.
What It Does: It allows multiple parts of an AI system to access data simultaneously without slowing down.
Why It Matters: Faster data access means shorter training times for AI models. This makes it easier for researchers to test new ideas quickly.

Day 6: DeepSeek-V3/R1 Inference System
What It Is: A system designed to make using AI models (inference) cheaper and faster while maintaining high quality.
What It Does: Handles millions of users with minimal hardware by dividing work across GPUs smartly. Achieves incredible efficiency—serving tens of millions of DAU’s inference demand (600 billion input tokens and 150 billion output tokens per day) with just ~2,200 GPUs.
Why It Matters: This system drastically reduces the cost of deploying advanced AI models, making them accessible even for smaller businesses. For example, DeepSeek outperformed expectations by serving massive user bases with far fewer resources than competitors.

Industry Implications
DeepSeek’s Open Source Week went largely under-covered by Western media this time. Still, it actually is quite important as it could redefine the economics of AI, the competitive landscape, and the pace of innovation across industries. Since the release of R1, we have known that we can actually cut costs in AI inference.
Now, with additional tools like FlashMLA and DeepEP, running large models will be much more accessible for startups and non-big tech companies. These tools are designed to optimize the performance of existing hardware, reducing costs while speeding up operations. And ultimately, consumers are the biggest beneficiaries, as this means cheaper and faster AI-powered services—like smarter chatbots, better recommendation systems, or even real-time language translation tools. This is a huge step toward democratizing AI infrastructure adoption acceleration across industries and potentially drawing in more AI users.
Economies of Scale
Due to economies of scale, DeepSeek’s innovations will actually amplify big tech’s reach even further. As these companies already serve massive user bases across various touchpoints, it means that with steady high demand for compute usage, you do not need to fear any spikes to maximize efficiency in their compute clusters.
For example, DeepSeek demonstrated that with a large enough user base, you may only need to provide 30% extra capacity instead of 3-5x the computing power that smaller companies would require. This “economies of scale” effect means that as these giants grow larger, their cost per user shrinks further, which further brings down the price of consumers using AI, cementing their dominance in consumer-facing AI services. This will probably be especially useful for Chinese big tech companies as they try to find ways to monetize AI in consumer-facing application use cases. This creates a virtuous cycle: lower costs lead to more users, which leads to even greater efficiency and cost savings.
However, as mentioned, this will help further democratize AI adoption. While big companies benefit from economies of scale, DeepSeek’s commitment to open-source its technologies does level the playing field for smaller players. Startups and mid-sized companies will be able to access cutting-edge tools without needing to invest millions in proprietary infrastructure or expensive GPUs. Hopefully, this will spark a wave of innovation from smaller teams who now have access to the same level of efficiency as industry leaders.
Final Thoughts
By serving tens of millions of daily active users (DAUs) with just 2,200 GPUs while processing 750 billion tokens daily, this is a fraction of the hardware competitors like OpenAI or Google are believed to use for similar workloads. What it means for the broader industry is that companies can no longer afford to be inefficient with their computing resources when DeepSeek has demonstrated that it can be done with much less. Value per GPU is the new key indicator added to measuring how good a model is.
As I’ve written before about - Jevons Paradox - as compute become cheaper and more efficient, demand will inevitably grow. So that brings us to one of the most provocative questions raised by DeepSeek’s innovations, which is whether we’re overestimating how much compute power is actually required today. Let’s break it down:
DeepSeek used just 2,200 GPUs to process 750 billion tokens daily while serving tens of millions of DAUs.
Extrapolating from this efficiency: 200,000 GPUs (roughly 5% of NVIDIA’s estimated 4 million Hopper GPUs sold in 2024) could theoretically handle 75 trillion tokens per day.
For context: The Information reported that OpenAI’s total daily API token usage as of January 2025 was around 2 trillion tokens per day—a fraction of the 75 trillion number above.
This past week seemed to further the narrative DeepSeek started with its R1 release in January. By proving that frontier performance can be achieved with far fewer resources than previously thought possible, DeepSeek has set new expectations for what efficient AI infrastructure looks like. We’ve heard this so many times now that necessity is the mother of innovation, but truly, this might not have happened if DeepSeek had the resources the big techs did—that is, capital and access to GPUs (in the U.S.).
To be honest, I don’t think the most pressing question is really about whether we’ll need more computing power right now—it’s how to use energy more efficiently to reach AGI goals while being mindful of our environmental and climate challenges. Jevons Paradox ensures that as we optimize today’s resources, tomorrow’s demand will only grow larger. But thanks to DeepSeek’s innovations, we now know how far those resources can stretch—and how much more is possible when efficiency takes center stage.
Hi Grace, good summary & succinct analyses of DeepSeek’s Open Source Week. Thank you for your article, saved me time in analysing the 6 releases!
Especially the 3 sections “What It Is” “What It Does” “Why It Matters”, plus your “Industry Implications” analysis. 👍
Well, just as pure speculation, suppose the Chinese government decided that disrupting American market hegemony is in their strategic best interests. What better way to do that than to make this sort of technology open source?